Введение
С выходом Zabbix версии 4.2 появилась поддержка в экспериментальном режиме TimescaleDB (TSDB). Это расширение для PostgreSQL, использующееся для хранения данных во временном порядке. Т.е. по сути появляется возможность нативного партиционирования из коробки.
В статье будет рассказано о данных в TSDB, партиционировании и установки всего этого в Docker. А т.к. поддержка timescale теперь официальная, то можно подготавливаться к использованию в продакшене.
Временные ряды и TimescaleDB
Ранее в качестве СУБД для Zabbix я всегда применял классический вариант – MySQL. А с ростом данных применял партиционирование . Этот способ до сих пор остаётся рабочим с классическим подходом через скрипты и процедуры. Но появляются постоянно новые вещи, на которые иногда нужно обращаться внимание. В частности, стало модно использовать NoSQL реализации СУБД, например, такие как InfluxDB.
Суть временных рядов заключается в хранении статистических данных за какой-то период в формате время-значение. А представляются такие данные в виде упорядоченных по времени блоков, проиндексированных по какому-то временному полю. Для выборки и последующих операций над данными необходимо обрабатывать много значений. А для реляционных СУБД такие запросы на выборку становятся не эффективными. И также создают эффект бутылочного горлышка при большой нагрузке и больших объемах данных.
Для систем мониторинга вышеописанный момент крайне критичен, т.к. могут получаться и обрабатываться сотни тысяч метрик в единицу времени, а потому в игру вступают NoSQL-решения. Но у них имеется недостаток – отсутствие поддержки SQL и совместимости с ним, а большинство из таких решений вообще не являются CRUD (Create, Read, Update, Delete).
Zabbix можно использовать NoSQL для хранения данных временных рядов, а всё остальное хранить в SQL-СУБД – это как вариант, но появляется дополнительная точка отказа и необходимость администрирования всего этого промежуточного огорода.
И вот тут в игру вступает TimescaleDB – это всего лишь расширение для классической PostgreSQL. TSDB позволяет отметить необходимую таблицу в качестве hypertable, а внутри неё создать фрагменты (chunks), в которых уже будут храниться временные данные. По сути это уровень абстракции, но в конечном счёте ни приложению и самой PSQL не надо знать, что под капотом используется какая-то “гипертаблица” и “чанки” – с таблицами можно продолжать классическое взаимодействие.
Графический пример гипертаблицы и чанков из официальной документации:
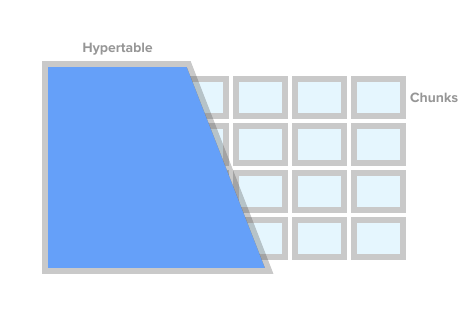
Если необходимо добавить новое значение временного ряда, TSDB направляет это значение в нужный фрагмент (чанк) и всё встает на свои места.
В целом и общем TSDB протестирован и является более производительным вариантом относительно MySQL или PSQL с их партиционированием, а потому самое время попробовать установить всё это хозяйство для Zabbix и проверить в бою.
Zabbix и TimescaleDB
Установка Zabbix будет осуществляться в контейнерах:
- zabbix-server
- zabbix-front
- database
Предварительно необходимо создать сеть для взаимодействия всех контейнеров:
sudo docker network create zabbix_netКонтейнеры, созданные в рамках данной сети, смогу видеть друг друга, в том числе по имени, которое передаётся через ключ –-name. Проверить это можно позднее, создав контейнеры и выполнить ping из одного контейнера в другой по указанному имени.
PostgreSQL & Timescaledb
Начнём с контейнера базы данных. Необходимо определить наименование контейнера и создать директорию для хранения постоянных данных, которые будут примонтированы в контейнер:
container_name=zab_tsdb
mkdir -p /storage/${container_name}/dataУстановка простая, на момент написания статьи устанавливается PostgreSQL 11 и timescaledb 1.7.3:
docker run -d --name ${container_name} \
-p 5432:5432 \
--restart=unless-stopped \
--network zabbix_net \
-v /storage/${container_name}/data:/var/lib/postgresql/data \
-e POSTGRES_PASSWORD=root \
timescale/timescaledb:1.7.3-pg11При необходимости можно настроить доступ к базе в pg_hba.conf только для созданного пользователя с нужного адреса.
После запуска контейнер уже сконфигурирован для оптимального использования благодаря использованию timescaledb-tune – утилиты от разработчиков tsdb, которая проверяет параметры ОС (память, процессор) и на их основе выставляет оптимальные значения в конфиге postgresql.conf. Очень даже удобно. При желании можно отключить, задав переменную окружения, а также отключить и телеметрию: NO_TS_TUNE=true и TIMESCALEDB_TELEMETRY=off. Вообще многие параметры настраиваются через переменные окружения, детальнее уже нужно смотреть документацию.
При необходимо можно запустить timescaledb-tune вручную в контейнере или же поправить конфиг на хост-машине по пути /storage/${container_name}/data/postgresql.conf и выполнить перезагрузку контейнера для применения. Также, некоторые параметры можно менять “на лету”.
Контейнер готов к работе, можно зайти вовнутрь и подключиться к консоли psql для проверки.
Теперь необходимо создать пустую базу и пользователя для Zabbix,Создать можно разными способами, я руководствовался оф. документацией Zabbix и выполнял команды изнутри контейнера под пользователем postgres:
docker exec -it ${container_name} bash
su - postgres
createuser --pwprompt zabbix # создается пользователь с вводом пароля
createdb -O zabbix -E Unicode -T template0 zabbix # создается БДКоманды выше создают пользователя с именем zabbix и базу данных на основе шаблона templtate0 (встроен в psql) с наименованием zabbix и указанием кодировки UTF-8. Посмотреть полученные результаты в консоли psql:
\l
\duИ последним этапом осталось наделить созданного пользователя правами к созданной базе, тут уже из консоли psql:
psql zabbix
GRANT ALL PRIVILEGES ON DATABASE zabbix to zabbix;Гвоздём программы является нативное партиционирование в TSDB и к нему надо будет вернуться после запуска сервера Zabbix, а пока просто достаточно включить расширение timescaledb:
psql zabbix
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Zabbix server
Контейнер с БД готов принимать данные, теперь необходимо “натравить” на него сам сервер Zabbix.
Переменные окружения выставлены самые основные, необходимо заменить на свой данные логин и пароль к БД + остальные параметры при необходимости, иначе можно оставить по умолчанию.
Рекомендуется выполнять запуск с монтированием нижеуказанных директорий, которые необходимо предварительно создать. Лучше создать их и держать пустыми, т.к. в будущем они могут понадобится и не придётся создавать контейнер заново:
container_name=zab_srv
mkdir -p /storage/${container_name}/usr/lib/zabbix/{externalscripts,modules,,mibs,snmptraps,alertscripts}И непосредственно сам запуск:
docker run -d --name ${container_name} \
-h ${container_name} \
--restart=unless-stopped \
--network zabbix_net \
-p 10051:10051 \
-e DB_SERVER_HOST=zab_tsdb \
-e POSTGRES_DB="zabbix" \
-e POSTGRES_USER="zabbix" \
-e POSTGRES_PASSWORD=zabbix \
-e ZBX_SERVER_NAME=${container_name} \
-e ZBX_STARTPOLLERS="15" \
-e ZBX_STARTPOLLERSUNREACHABLE="5" \
-e ZBX_STARTTRAPPERS="5" \
-e ZBX_STARTDISCOVERERS="1" \
-e ZBX_STARTHTTPPOLLERS="1" \
-e ZBX_STARTTIMERS="1" \
-e ZBX_STARTESCALATORS="1" \
-e ZBX_SENDERFREQUENCY="30" \
-e ZBX_CACHESIZE="16M" \
-e ZBX_CACHEUPDATEFREQUENCY="60" \
-e ZBX_STARTDBSYNCERS="4" \
-e ZBX_HISTORYCACHESIZE="16M" \
-e ZBX_HISTORYINDEXCACHESIZE="4M" \
-e ZBX_TRENDCACHESIZE="4M" \
-e ZBX_VALUECACHESIZE="8M" \
-e ZBX_TRAPPERIMEOUT="300" \
-e ZBX_STARTPROXYPOLLERS="1" \
-e ZBX_STARTDBSYNCERS="5" \
-e ZBX_TIMEOUT="10" \
-e TZ="Europe/Moscow" \
-v /storage/${container_name}/usr/lib/zabbix/externalscripts:/usr/lib/zabbix/externalscripts \
-v /storage/${container_name}/var/lib/zabbix/modules:/var/lib/zabbix/modules \
-v /storage/${container_name}/var/lib/zabbix/mibs:/var/lib/zabbix/mibs \
-v /storage/${container_name}/var/lib/zabbix/snmptraps:/var/lib/zabbix/snmptraps \
-v /storage/${container_name}/usr/lib/zabbix/alertscripts:/usr/lib/zabbix/alertscripts \
zabbix/zabbix-server-pgsql:alpine-5.0.3Можно в отдельном окне терминала запустить логи и смотреть, как проходит инициализация. Например, будет видно, что Zabbix увидел созданную базу и импортирует в неё схему: “Creating ‘zabbix’ schema in PostgreSQL…”
При запуске контейнера с сервером Zabbix, помимо других основных переменных окружения, указанных в документации на Dockerhub, можно указать переменную ENABLE_TIMESCALEDB=true (в доке она не описана почему-то) и тогда в скрипте entrypoint будет включено расширение timescaledb для postgres и выполнен импорт sql-файла с указанием создания гипертаблиц и чанков, т.е. включение партиционирования.
Но так как все действия в базе выполнялись вручную, то запрос по созданию гипертаблиц лучше выполнить также вручную, к тому же здесь можно переопределить дефолтное значение периода хранения чанков, т.е. данных – иногда это бывает критично, т.к. положено хранить данные n месяцев, например. Предварительно сервер zabbix лучше остановить, чтобы данные не поступали на момент создания гипертаблиц:
docker stop zab_srvТакже остался вопрос по выбору размера чанков. Тут всё зависит от данных, которые будут поступать в Zabbix. Например, если около 10 Гб в день, то лучше чанки разбивать по дням. Но, как обычно бывает, данных сначала мало, а потом становится слишком много, стоит об этом заранее подумать и выбрать оптимальное значение для определенных таблиц. По умолчанию чанки разбиваются по месяцам.
Итого мой запрос выглядит так (по сути ничем не отличается от того, что в оф. образе). Исторические данные разбиваются по дням, тренды по месяцам:
docker exec -it zab_tsdb bash
su - postgres
psql -d zabbix -c "SELECT create_hypertable('history', 'clock', chunk_time_interval => 86400, migrate_data => true);"
psql -d zabbix -c "SELECT create_hypertable('history_uint', 'clock', chunk_time_interval => 86400, migrate_data => true);"
psql -d zabbix -c "SELECT create_hypertable('history_log', 'clock', chunk_time_interval => 86400, migrate_data => true);"
psql -d zabbix -c "SELECT create_hypertable('history_text', 'clock', chunk_time_interval => 86400, migrate_data => true);"
psql -d zabbix -c "SELECT create_hypertable('history_str', 'clock', chunk_time_interval => 86400, migrate_data => true);"
psql -d zabbix -c "SELECT create_hypertable('trends', 'clock', chunk_time_interval => 2592000, migrate_data => true);"
psql -d zabbix -c "SELECT create_hypertable('trends_uint', 'clock', chunk_time_interval => 2592000, migrate_data => true);"
psql -d zabbix -c "UPDATE config SET db_extension='timescaledb',hk_history_global=1,hk_trends_global=1;"
psql -d zabbix -c "UPDATE config SET compression_status=1,compress_older='7d';"Zabbix front
Осталось запустить фронт, здесь в общем-то и описывать нечего, всё стандарта и минимум переменных для запуска, один момент только – порт внутри контейнера с Nginx 8080 – по всей видимости это сделано для того, чтобы можно было запускать nginx от имени непривилегированного пользователя:
container_name=zab_front
docker run -d --name ${container_name} \
-h ${container_name} -p 80:8080 \
--network zabbix_net \
-e DB_SERVER_HOST=zab_tsdb \
-e POSTGRES_DB="zabbix" \
-e POSTGRES_USER="zabbix" \
-e POSTGRES_PASSWORD=zabbix \
--restart unless-stopped \
-e TZ="Europe/Moscow" \
-e PHP_TZ="Europe/Moscow" \
-e ZBX_SERVER_HOST=zab_srv \
zabbix/zabbix-web-nginx-pgsql:alpine-5.0.3После запуска необходимо убедиться, что все контейнеры запущены, и тогда в браузере по адресу http://localhost:80 можно постучаться в морду с логином Admin и паролем zabbix в веб-морду.
В настройках можно увидеть, что данные в таблицах истории и динамики изменений можно хранить необходимое количество дней и переопределить это значение при необходимости. И главная фишка – есть возможность сжимать данные, если они старше семи дней — это значительно позволяет сэкономить место на диске. Сжатие активируется по дефолту благодаря запросу “UPDATE config SET compression_status=1,compress_older=’7d’;”, пример на скриншоте ниже:

Итого по данной инструкции можно настроить производительную систему мониторинга с использованием расширения timescaledb для postgresql и zabbix 5.0.3 на момент написания статьи – всё корректно работает из коробки и никаких костылей\велосипедов с использованием скриптов и процедур, как это было в MySQL.