- Введение
- Подготовительные работы
- Описание используемого стека
- VictoriaMetrics
- Loki
- Grafana
- Общие сведения перед запуском
- VictoriaMetrics и Grafana
- Loki
- Подготовка репозитория
- Общие сведения
- VictoriaMetrics
- Grafana
- Мониторинг Flux
- Alertmanager
- Loki
- Nginx Ingress Controller
- Деплой в кластер
- Доступ к ресурсам
- Метрики
- Алерты
- Логи
- Заключение
- Используемые источники
Введение
В данной статье будет рассмотрен пример настройки мониторинга кластера Kubernetes на основе стека VictoriaMetrics, Loki и Grafana. Деплой этих инструментов будет осуществляться через GitOps-подход с использованием CD-утилиты Flux2, а вся конфигурация будет располагаться в системе контроля версий.
Основной акцент сделан на структуру git-репозитория и возможности flux с кратким описанием используемых компонентов мониторинга.
Также можно ознакомиться с предыдущей статьей.
Подготовительные работы
Для дальнейшей работы понадобится:
- консольный клиент для начальной установки flux в кластер K8s
- доступ к github-репозиторию через токен с правами на запись (также подойдут gitlab и прочие)
Все нижеописанные действия в теории должны быть без проблем воспроизведены на любом Kubernetes-кластере. В данном случае используется Docker Desktop для Windows и Kubernetes актуальной на момент написания версии — 1.24 (который уже без dockershim).
Описание используемого стека
Ниже будут даны краткие описания по стеку и его дальнейшей установке.
VictoriaMetrics
VictoriaMetrics — СУБД временных рядов, является совместимым «заменителем» Prometheus, которую можно использовать для более сложных конфигураций, где имеется очень большой поток метрик. Более подробно про различия виктории и прометея можно посмотреть, например, в этой статье.
В VictoriaMetrics имеются следующие основные компоненты, необходимые для организации мониторинга:
- vmagent — собирает метрики от различных exporter`ов и отправляет их в СУБД vmsingle
- vmalert — работает с rules и отправляет алерты через Alertmanager
- vmsingle — непосредственно инстанс СУБД самой виктории
Loki
Мониторинг — это не только метрики CPU и RAM, но и логи приложений. Именно эту роль и выполняет Loki, сохраняя в себя логи подов и системных компонентов кластера k8s.
Loki основан на идее индексировать только метаданные логов — labels (так же, как и в Prometheus), группируя данные в потоки, a сами логи сжимать рядом в отдельные чанки.

Таким образом достигается скорость работы по сравнению с тем же Elasticsearch, когда индексируется лог целиком.
Loki поддерживает язык запросов LogQL, которым можно оперировать для получения логов из Grafana (или откуда-то ещё).
Также можно воспользоваться Alertmanager для настройки алертов\уведомлений, как и для VictoriaMetrics, но только для логов из Loki.
Promtail является агентом, который собирает логи для отправки их в хранилище. Перед отправкой он обогащает лог необходимыми labels. Вместо Promtail также можно использовать и fluentbit, fluentd.
Grafana
Графана используется для отрисовки графиков и вывода значений из источника данных, в роли которого выступает VictoriaMetrics или Loki. Данные выводятся на основе языка запросов MetricsQL, который обратно совместим и с PromQL.
Общие сведения перед запуском
VictoriaMetrics и Grafana
Для работы VictoriaMetrics необходимы некоторые зависимости:
- Grafana для отрисовки дашбордов
- Node-exporter для снятия метрик с кубернетес-нод
- Alertmanager для отправки уведомлений
Помимо этого есть ещё две обособленные зависимости:
- kube-state-metrics — аддон для получения метрик Kubernetes-кластера
- Kubernetes-оператор VictoriaMetrics — оператор с кастомными CRD для взаимодействия с VictoriaMetrics. Совместим как с типами прометеус-оператора, так и позволяет использовать свои собственные типа
VMPodScrape,VMRuleи т.д.
Всё вышеописанное можно установить по отдельности. Но это может быть сложно и наверняка на каком-то этапе возникнет путаница. Поэтому лучше воспользоваться готовым Helm-чартом, в котором эти зависимости учтены и выполняется установка всего необходимого «из коробки» с возможностью кастомизации при необходимости. Есть чарт как для установки простой VictoriaMetrics в кубере в полу-ручном режиме, а также чарт victoria-metrics-k8s-stack полностью со всеми зависимостями — экспортером, оператором, алертменеджером и т.д. В данном случае будет использоваться второй вариант чарта.
Loki
С Loki аналогичная ситуация, как и выше — есть возможность запуска через манифесты, и есть готовые helm-чарты. В данном случае будет использоваться loki-stack, который содержит в себе сам Loki и Promtail.
Подготовка репозитория
Общие сведения
Loki и VictoriaMetrics можно считать как инфраструктурные объекты, поэтому они будут расположены в каталоге gitops/infra. Данный подход не является обязательным, логически можно разместить как угодно. В этот же каталог infra добавляется Nginx Ingress Controller.
Подготовить каталоги:
mkdir -p monitoring/gitops/infra/{logs,monitoring}/scrape
mkdir -p monitoring/gitops/infra/monitoring/dashboardsУпрощенная структура гит-репозитория на первоначальном этапе для наглядности:
tree -d
.
└── gitops
└── infra
├── ingress-controller
├── logs
└── monitoringДалее будет разбор структуры и описание создаваемых конфигурационных файлов по ходу дела.
VictoriaMetrics
Создать сущность HelmRepository:
cat > monitoring/gitops/infra/monitoring/helm-repository.yaml << EOF
---
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
metadata:
name: victoria-metrics
spec:
interval: 5h
timeout: 5m
url: https://victoriametrics.github.io/helm-charts/
EOFСоздать сущность HelmRelease с именем victoria-metrics:
cat > monitoring/gitops/infra/monitoring/helm-release.yaml << EOF
---
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: victoria-metrics
spec:
interval: 5m
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
targetNamespace: metrics
chart:
spec:
chart: victoria-metrics-k8s-stack
version: 0.8.3
sourceRef:
kind: HelmRepository
name: victoria-metrics
valuesFrom:
- kind: ConfigMap
name: victoria-metrics-values
- kind: ConfigMap
name: alertmanager-config-values
EOFВ HelmRelease указывается ссылка на HelmRepository, созданный ранее. Указывается targetNamespace с именем metrics — именно в этот namespace будут установлены все манифесты. И также указывается, что необходимо использовать values из ConfigMap victoria-metrics-values и alertmanager-config-values — об этом будет рассказано далее.
Базовые сущности добавлены, но при деплое чарта необходимо указать дополнительные значения в values. Чтобы их применить, создается файл values.yaml:
cat > monitoring/gitops/infra/monitoring/values.yaml << EOF
nameOverride: victoria-metrics
prometheus-node-exporter:
hostRootFsMount: false
vmsingle:
# https://github.com/VictoriaMetrics/operator/blob/master/docs/api.MD#vmsinglespec
spec:
extraArgs:
vmalert.proxyURL: http://vmalert-metrics-victoria-metrics:8080
# Grafana
# Sources
grafana:
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Loki
# change namespace 'logs' for your own if necessary
url: http://loki-stack.logs.svc:3100
type: loki
access: proxy
version: 1
editable: false
# - name: VictoriaMetrics # added by default from helm chart vm-k8s-stack
# url: http://vmsingle-metrics-victoria-metrics.metrics:8429
# type: prometheus
# access: proxy
# isDefault: true
EOFВ данном файле важно указать nameOverride: victoria-metrics с именем релиза, т.к. в исходном чарте значение nameOverride пустое. Остальные параметры относятся к самой виктории и зависимым компонентам:
- hostRootFsMount: false указывается для prometheus-node-exporter, иначе есть проблемы с запуском на Docker Desktop, issue
- vmalert.proxyURL указывается для vmsingle, т.е. инстанса VictoriaMetrics, чтобы в графане можно было получить список алертов — в качестве значения нужно указать имя сервиса vmalert и его порт
- datasources графаны указан для получения значений из loki, об этом будет рассказано далее
Далее необходимо создать новый ресурс — namespace — уже для kubernetes:
cat > monitoring/gitops/infra/monitoring/namespace.yaml << EOF
apiVersion: v1
kind: Namespace
metadata:
name: metrics
EOFТеперь все вышеописанные ресурсы необходимо указать в другом ресурсе — Kustomize:
cat > monitoring/gitops/infra/monitoring/kustomization.yaml << EOF
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: metrics
resources:
- helm-repository.yaml
- helm-release.yaml
- namespace.yaml
- dashboards
configMapGenerator:
- name: victoria-metrics-values
files:
- values.yaml=values.yaml
- name: alertmanager-config-values
files:
- values.yaml=alertmanager-config-values.yaml
configurations:
- kustomizeconfig.yaml
EOFВ Kustomization перечисляется всё то, что было создано ранее и создает configMap в Kubernetes на основе values.yaml. Таким образом всё, что было указано в values.yaml, будет создано через Kustomization и указывается в HelmRelease для использования. Но чтобы при изменении значений в values.yaml эти изменения были «замечены» кластером K8s создается ресурс kustomizeconfig.yaml, который генерирует configMap с новым именем (типа values-release-fh5h) и подключает в манифест:
cat > monitoring/gitops/infra/monitoring/kustomizeconfig.yaml << EOF
nameReference:
- kind: ConfigMap
version: v1
fieldSpecs:
- path: spec/valuesFrom/name
kind: HelmRelease
EOFЭто тоже самое, как если бы был скачан чарт локально, в values.yaml внесены значения и применены через helm install, только через хитрые абстракции Flux.
Grafana
Так как графана является зависимым чартом в чарте victoria-metrics-k8s-stack, то большая часть настроек уже выполнена или выполняется из коробки и делать ничего не нужно: помимо самой графаны в поде содержится ещё sidecar, который подключает дашборды в UI. Каждый дашборд — это json-файл. И чтобы это всё оказалось в K8s, создается configMap с нужным дашбордом и ему назначается метка grafana_dashboard: "1". Таким образом sidecar может узнать, что данный дашборд необходимо подключить в UI. По умолчанию дашборды выкачиваются через sidecar, поэтому специально для этого ничего делать не нужно.
В поле datasources файла monitoring/values.yaml был подключен источник данных — Loki. Это сделано сразу, т.к. он в дальнейшем понадобится. Остальные настройки графаны в данном случае можно оставить без изменений — helm-чарт сам установит нужные базовые дашборды, с помощью которых можно будет смотреть графики кластера кубернетес и его ресурсов.
Мониторинг Flux
Чарт victoriametrics содержит в себе набор дефолтных параметров для мониторинга. Но сам Flux (точнее его контроллеры) умеют отдавать метрики в prometheus-формате, на основе которых можно также строить графики и следить уже за работой самого приложения. Поэтому далее будет описана настройка мониторинга самого флакса.
Для отправки данных в vmsingle нужно создать манифест с типом VMPodScrape — при его наличии оператор VictoriaMetrics поймёт, что нужно собирать метрики с указанных приложений и порта:
mkdir -p monitoring/gitops/infra/monitoring/scrape
cat > monitoring/gitops/infra/monitoring/scrape/flux-podscrape.yaml << EOF
---
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMPodScrape
metadata:
name: fluxcd-pod-scrape
namespace: flux-system
spec:
namespaceSelector:
matchNames:
- flux-system
podMetricsEndpoints:
- port: http-prom
selector:
matchExpressions:
- key: app
operator: In
values:
- helm-controller
- source-controller
- kustomize-controller
- notification-controller
- image-automation-controller
- image-reflector-controller
EOFЕсли посмотреть манифесты флакса, в них можно найти порт с именем http-prom, с которого и отдаются метрики. А при наличии VMPodScrape они будут отправлены в vmsingle.
Но для просмотра метрик flux понадобится создать кастомный дашборд в графане через код. Необходимо, как сказано ранее выше, создать конфигмап с нужной меткой и дальше sidecar всё сделает сам. Поэтому создается каталог и в нём пара файлов json:
mkdir -p monitoring/gitops/infra/monitoring/dashboardsФайлы json доступны в исходном репозитории Flux, их необходимо разместить в каталог, созданный командой выше.
И указать эти файлы в кастомайз:
cat > monitoring/gitops/infra/monitoring/dashboards/kustomization.yaml << EOF
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
configMapGenerator:
- name: grafana-dashboards
options:
labels:
grafana_dashboard: "1"
files:
- flux-cluster.json
- flux-control-plane.json
EOFТаким образом:
- будут созданы кастомные дашборды для Flux
- будет осуществлён сбор метрик с приложения Flux
- будет указан новый источник данных (локи) в дополнение к дефолтному (vmsingle)
Alertmanager
Alertmanager идёт как зависимый компонент виктории, поэтому он также будет установлен по умолчанию + из коробки будут уже некоторые правила для алертов.
В рамках данной статьи будет настроена отправка оповещений через smtp на почту. Для этого создаётся отдельный файл values.yaml из которого также генерируется конфигмап и подключается в helm-release:
cat > monitoring/gitops/infra/monitoring/alertmanager-config-values.yaml << EOF
alertmanager:
config:
global:
resolve_timeout: 5m
smtp_smarthost: smtp.example.com:25
smtp_from: 'Alertmanager <admin@it-lux.ru>'
templates:
- "/etc/vm/configs/**/*.tmpl"
route:
group_by: ["alertgroup", "job"]
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: "send_email"
routes:
- matchers:
- severity=~"info|warning|critical"
receiver: send_email
receivers:
- name: send_email
email_configs:
- to: your_email@examle.ru
send_resolved: true
auth_username: your_email@examle.ru
auth_password: <strong_pass>
require_tls: false
EOFLoki
В случае с Loki основная часть выполняется по аналогии с созданием нужных ресурсов для установки из официального helm-чарта.
cat > monitoring/gitops/infra/logs/helm-repository.yaml << EOF
---
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
metadata:
name: loki-stack
spec:
interval: 5h
timeout: 5m
url: https://grafana.github.io/helm-charts
EOFcat > monitoring/gitops/infra/logs/helm-release.yaml << EOF
---
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: loki-stack
spec:
interval: 5m
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
releaseName: loki-stack
targetNamespace: logs
chart:
spec:
chart: loki-stack
sourceRef:
kind: HelmRepository
name: loki-stack
version: "2.6.4"
valuesFrom:
- kind: ConfigMap
name: loki-values
EOFБольшая часть настроек остаётся по умолчанию. В этом чарте графана тоже включена в зависимости и её нужно отключить, т.к. она уже будет задеплоена через чарт VoctoriaMetrics:
cat > monitoring/gitops/infra/logs/values.yaml << EOF
grafana:
enabled: false
EOFСоздать отдельный namespace с именем logs.
cat > monitoring/gitops/infra/logs/namespace.yaml << EOF
apiVersion: v1
kind: Namespace
metadata:
name: logs
EOFДля возможности мониторинга за Loki можно также создать отдельный ресурс виктории для сборки метрик в прометеус-формате:
mkdir -p monitoring/gitops/infra/logs/scrape/
cat > monitoring/gitops/infra/logs/scrape/loki-pod-scrape.yaml << EOF
---
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMPodScrape
metadata:
name: loki-pod-scrape
spec:
podMetricsEndpoints:
- port: http-metrics
selector:
matchExpressions:
- key: app
operator: In
values:
- loki
- promtail
EOFcat > monitoring/gitops/infra/logs/scrape/kustomization.yaml << EOF
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: logs
resources:
- loki-pod-scrape.yaml
EOFВ данном случае также нужно будет указать зависимость ресурса VMPodScrape от оператора виктории — см. далее по тексту.
Далее создать kustomize и указать все ресурсы:
cat > monitoring/gitops/infra/logs/kustomization.yaml << EOF
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: logs
resources:
- helm-repository.yaml
- helm-release.yaml
- namespace.yaml
configMapGenerator:
- name: loki-values
files:
- values.yaml=values.yaml
configurations:
- kustomizeconfig.yaml
EOFcat > monitoring/gitops/infra/logs/kustomizeconfig.yaml << EOF
nameReference:
- kind: ConfigMap
version: v1
fieldSpecs:
- path: spec/valuesFrom/name
kind: HelmRelease
EOFNginx Ingress Controller
Тут всё аналогично и дефолтно по настройкам:
mkdir -p monitoring/gitops/infra/ingress-controller
cat > monitoring/gitops/infra/ingress-controller/helm-repository.yaml << EOF
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: HelmRepository
metadata:
name: bitnami
spec:
interval: 30m
url: https://charts.bitnami.com/bitnami
EOFВыбран тип сервиса NodePort, при необходимости можно изменить:
cat > monitoring/gitops/infra/ingress-controller/helm-release.yaml << EOF
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: nginx
spec:
releaseName: nginx-ingress-controller
chart:
spec:
chart: nginx-ingress-controller
sourceRef:
kind: HelmRepository
name: bitnami
version: "9.1.27"
interval: 1h0m0s
install:
remediation:
retries: 3
# Default values
# https://github.com/bitnami/charts/blob/master/bitnami/nginx-ingress-controller/values.yaml
values:
service:
type: NodePort
EOFcat > monitoring/gitops/infra/ingress-controller/namespace.yaml << EOF
apiVersion: v1
kind: Namespace
metadata:
name: infra
EOFЗдесь не указывается kustomizeconfig, потому что не используются configmap с values.yaml для helmrelease:
cat > monitoring/gitops/infra/ingress-controller/kustomization.yaml << EOF
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: infra
resources:
- namespace.yaml
- helm-release.yaml
- helm-repository.yaml
EOFСтруктура репозитория должна выглядеть таким образом на данный момент:
monitoring/
└── gitops
└── infra
├── ingress-controller
│ ├── helm-release.yaml
│ ├── helm-repository.yaml
│ ├── kustomization.yaml
│ └── namespace.yaml
├── logs
│ ├── helm-release.yaml
│ ├── helm-repository.yaml
│ ├── kustomization.yaml
│ ├── kustomizeconfig.yaml
│ ├── namespace.yaml
│ ├── scrape
│ │ ├── kustomization.yaml
│ │ └── loki-pod-scrape.yaml
│ └── values.yaml
└── monitoring
├── alertmanager-config-values.yaml
├── dashboards
│ ├── flux-cluster.json
│ ├── flux-reconcilation.json
│ └── kustomization.yaml
├── helm-release.yaml
├── helm-repository.yaml
├── kustomization.yaml
├── kustomizeconfig.yaml
├── namespace.yaml
├── scrape
│ └── flux-podscrape.yaml
└── values.yamlДеплой в кластер
Все ресурсы подготовлены и могут быть установлены в кластере Kubernetes. Осталось проинформировать об этом сам Flux.
Создать каталог:
mkdir -p monitoring/gitops/clusters/mycluster/infra/И разместить в нём манифесты с типом Kustomization (kustomize.toolkit.fluxcd.io/v1beta2)
Nginx Ingress:
cat > monitoring/gitops/clusters/mycluster/infra/ingress-controller.yaml << EOF
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: nginx-ingress
namespace: flux-system
spec:
interval: 10m0s
path: ./gitops/infra/ingress-controller
prune: true
sourceRef:
kind: GitRepository
name: flux-system
EOFLoki:
cat > monitoring/gitops/clusters/mycluster/infra/logs.yaml << EOF
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: logs
namespace: flux-system
spec:
interval: 1m0s
path: ./gitops/infra/logs
prune: true
sourceRef:
kind: GitRepository
name: flux-system
EOFИ момент с указанием зависимостей, о котором говорилось ранее:
cat > monitoring/gitops/clusters/mycluster/infra/logs-scrape.yaml << EOF
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: logs-scrape
namespace: flux-system
spec:
dependsOn:
- name: metrics
interval: 1m0s
path: ./gitops/infra/logs/scrape
prune: true
sourceRef:
kind: GitRepository
name: flux-system
EOFВ данном манифесте указывается dependsOn со ссылкой на чарт VictoriaMetrics.
VictoriaMetrics:
cat > monitoring/gitops/clusters/mycluster/infra/metrics.yaml << EOF
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: metrics
namespace: flux-system
spec:
interval: 1m0s
path: ./gitops/infra/monitoring
prune: true
sourceRef:
kind: GitRepository
name: flux-system
EOFИ снова зависимый манифест:
cat > monitoring/gitops/clusters/mycluster/infra/metrics-scrape.yaml << EOF
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: metrics-scrape
namespace: flux-system
spec:
dependsOn:
- name: metrics
interval: 1m0s
path: ./gitops/infra/monitoring/scrape
prune: true
sourceRef:
kind: GitRepository
name: flux-system
EOFФинальный вид репозитория:
monitoring/
└── gitops
├── clusters
│ └── mycluster
│ └── infra
│ ├── ingress-controller.yaml
│ ├── logs-scrape.yaml
│ ├── logs.yaml
│ ├── metrics-scrape.yaml
│ └── metrics.yaml
└── infra
├── ingress-controller
│ ├── helm-release.yaml
│ ├── helm-repository.yaml
│ ├── kustomization.yaml
│ └── namespace.yaml
├── logs
│ ├── helm-release.yaml
│ ├── helm-repository.yaml
│ ├── kustomization.yaml
│ ├── kustomizeconfig.yaml
│ ├── namespace.yaml
│ ├── scrape
│ │ ├── kustomization.yaml
│ │ └── loki-pod-scrape.yaml
│ └── values.yaml
└── monitoring
├── alertmanager-config-values.yaml
├── dashboards
│ ├── flux-cluster.json
│ ├── flux-reconcilation.json
│ └── kustomization.yaml
├── helm-release.yaml
├── helm-repository.yaml
├── kustomization.yaml
├── kustomizeconfig.yaml
├── namespace.yaml
├── scrape
│ └── flux-podscrape.yaml
└── values.yamlМожно деплоить. Зафиксировать изменения в гите:
git add . && git commit -m "install vm, loki, nginx"
git pull origin main\masterЗапустить Flux2:
export GITHUB_TOKEN=<your_token_from_gh>
export GITHUB_USER=rmn-lux
export REPO=monitoring
export OWNER=rmn-lux
flux bootstrap github \
--owner=$OWNER \
--repository=$REPO \
--branch=main \ # обратить внимание на ветку - должна быть main или master
--path=gitops/clusters/mycluster \
--personalДля проверки получить все ресурсы флакса:
flux get all -A
Доступ к ресурсам
Для production-решений дополнительно как минимум понадобится настроить ingress и TLS-сертификаты в values.yaml чарта. В рамках данной статьи для упрощения доступ в графану можно получить через kubectl port forward:
export POD_NAME=$(kubectl get pods --namespace metrics -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=metrics-victoria-metrics" -o jsonpath="{.items[0].metadata.name}")
# get grafana secret
kubectl get secret --namespace metrics metrics-victoria-metrics-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
kubectl --namespace metrics port-forward $POD_NAME 3000Теперь через браузер с логином admin и паролем из secret можно залогиниться в графану на http://localhost:3000:
Метрики
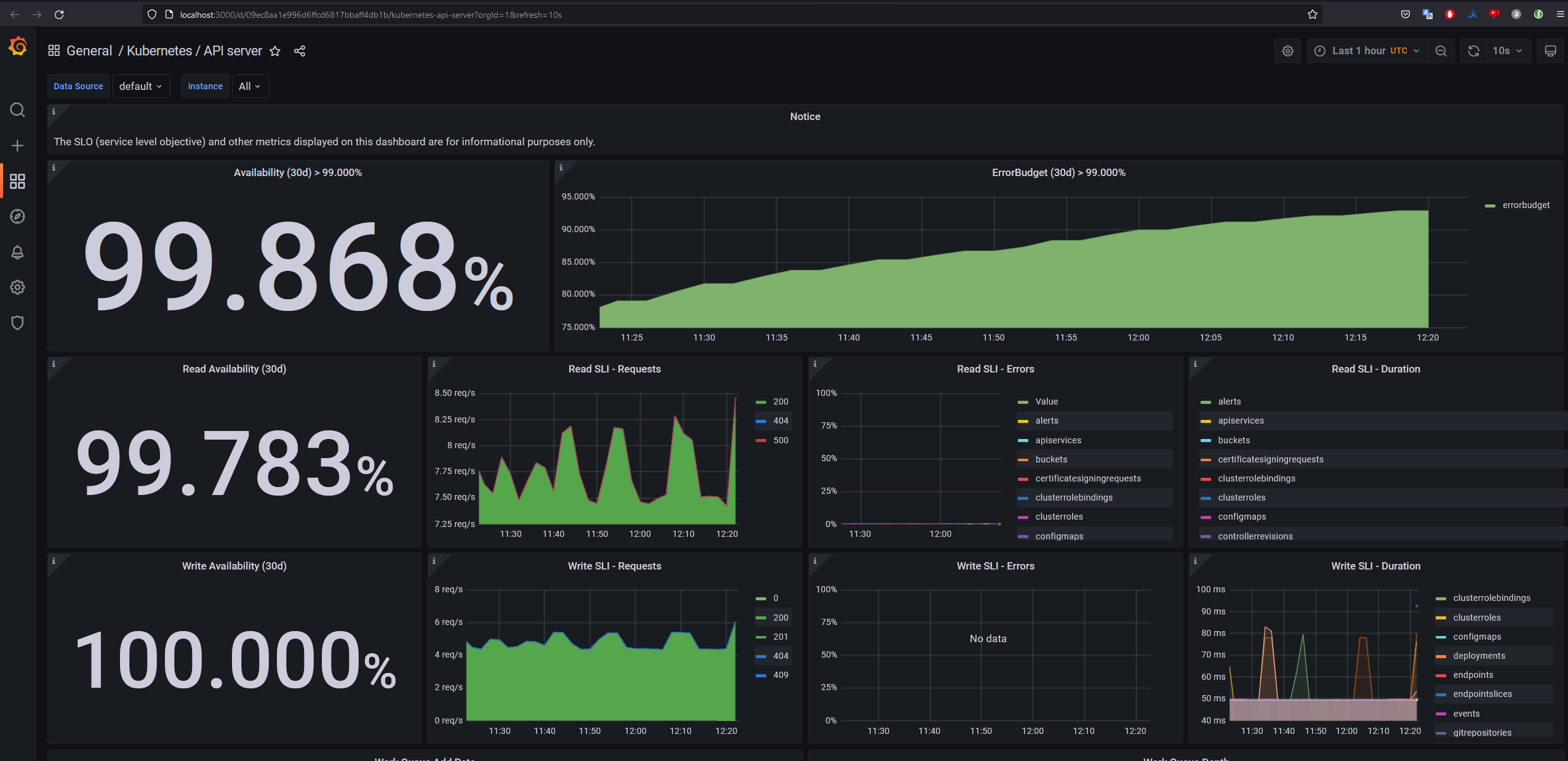
В разделе dashboards будут доступны различные дашборды с панелями графиков. Например, графики для Kubernetes API Server:
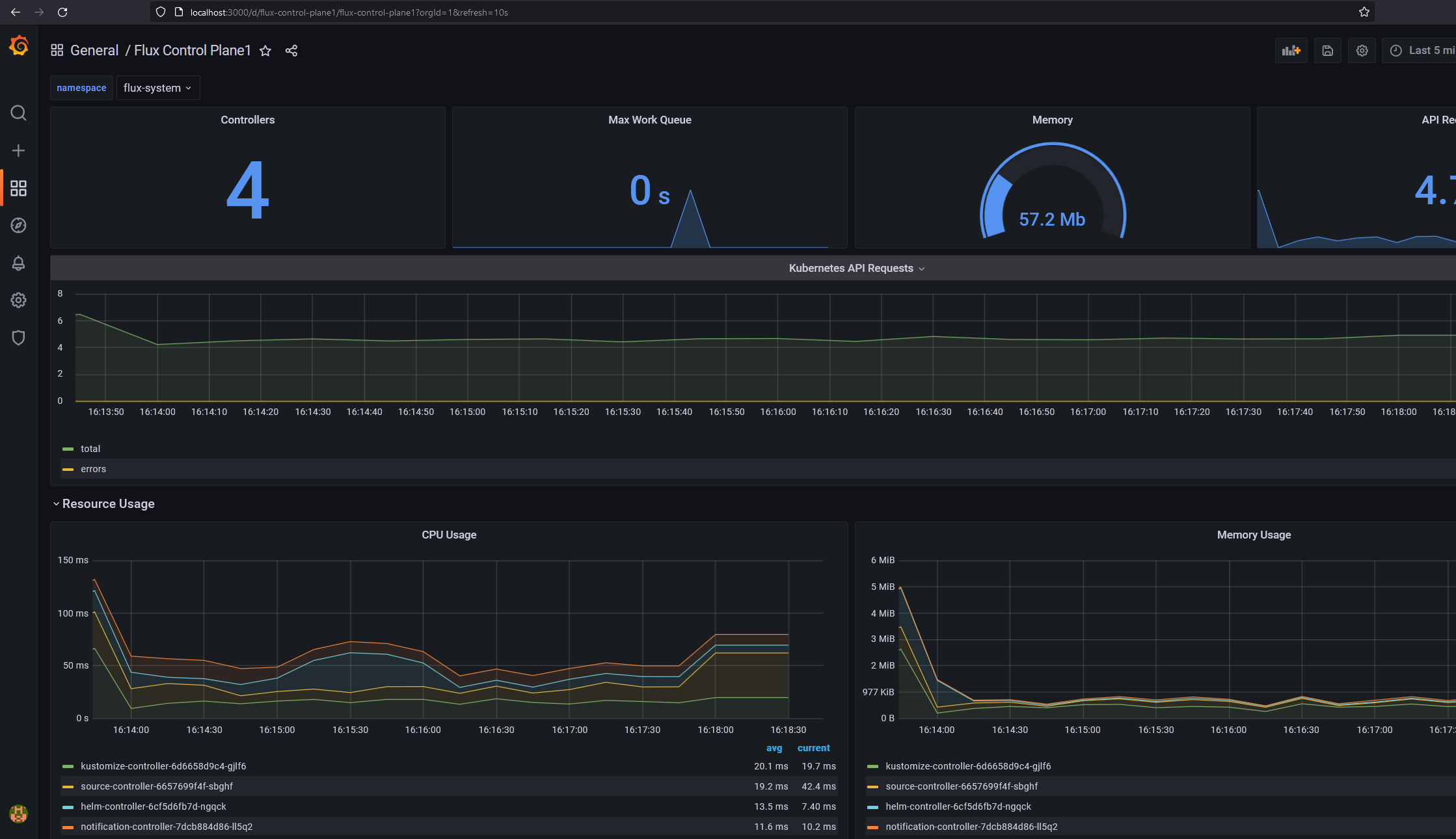
А также кастомные дашборды для мониторинга Flux:
Алерты
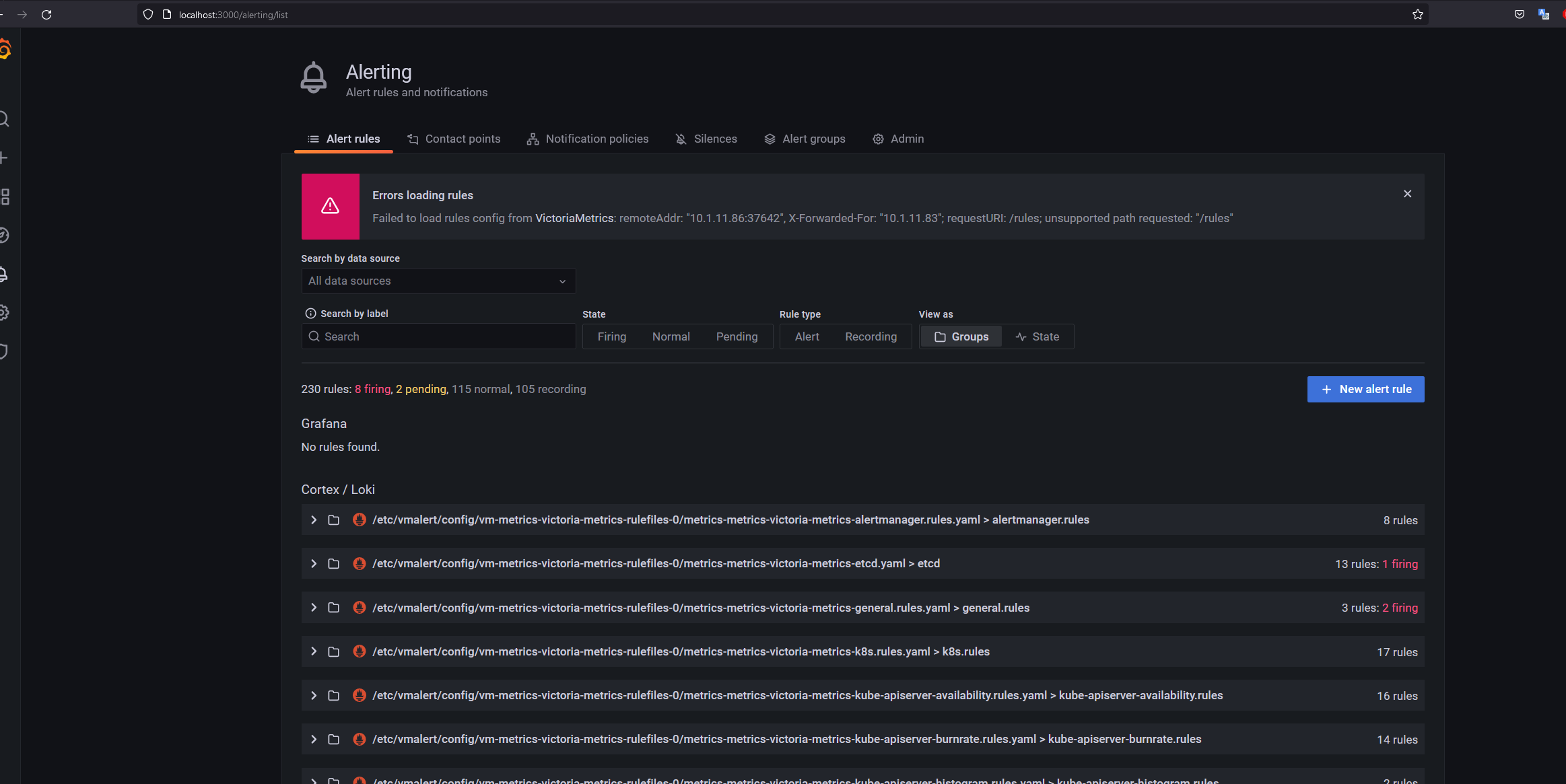
Через графану также можно получить список настроенных алертов, которые уже были из коробки в чарте.
Но вообще можно получить визуализацию и через сам vmalert.
Логи
Для получения логов из Loki необходимо перейти в раздел Explore, выбрать источник данных Loki и выбрать необходимые метки. Например, под с Nginx Ingress Controller:
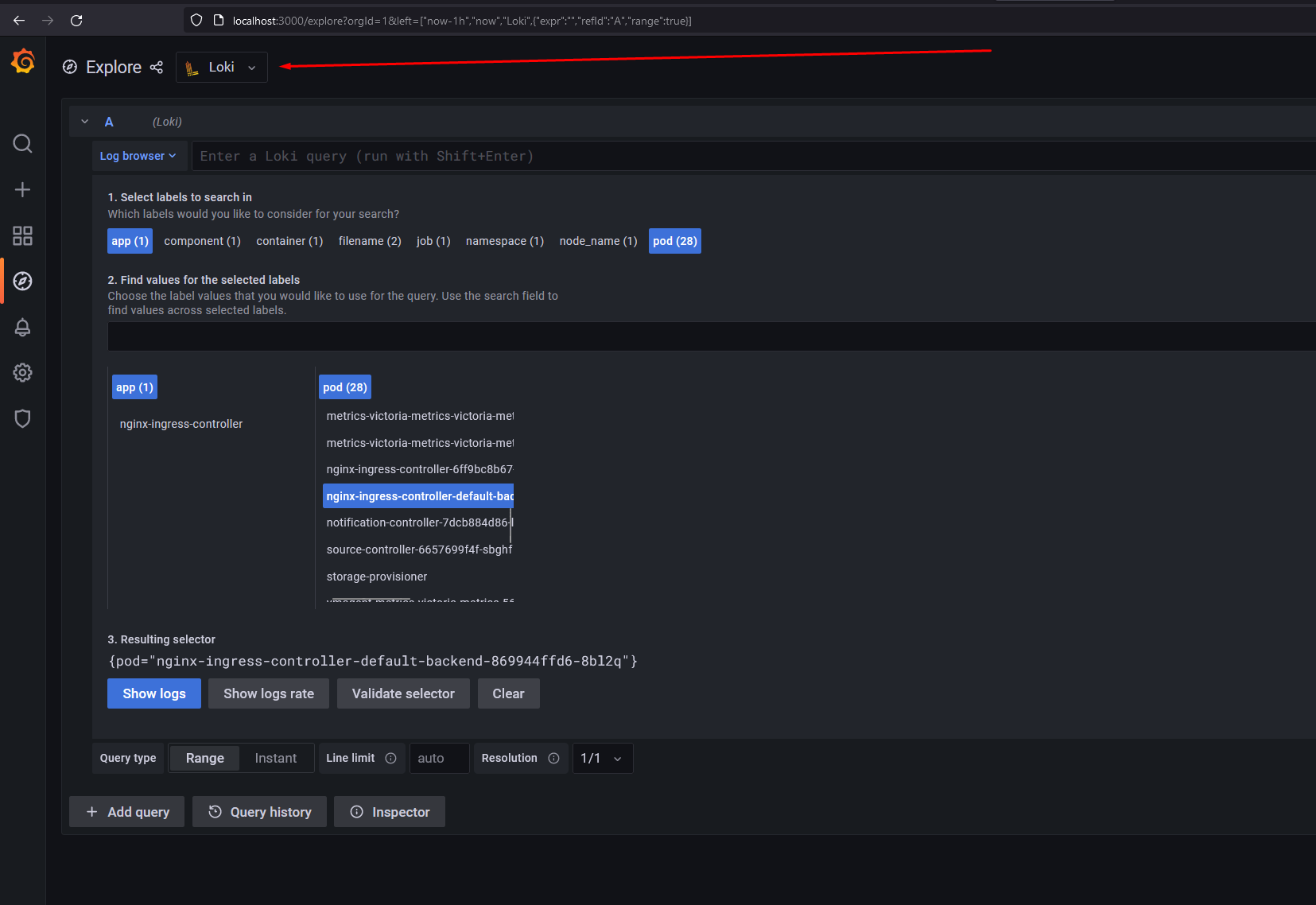
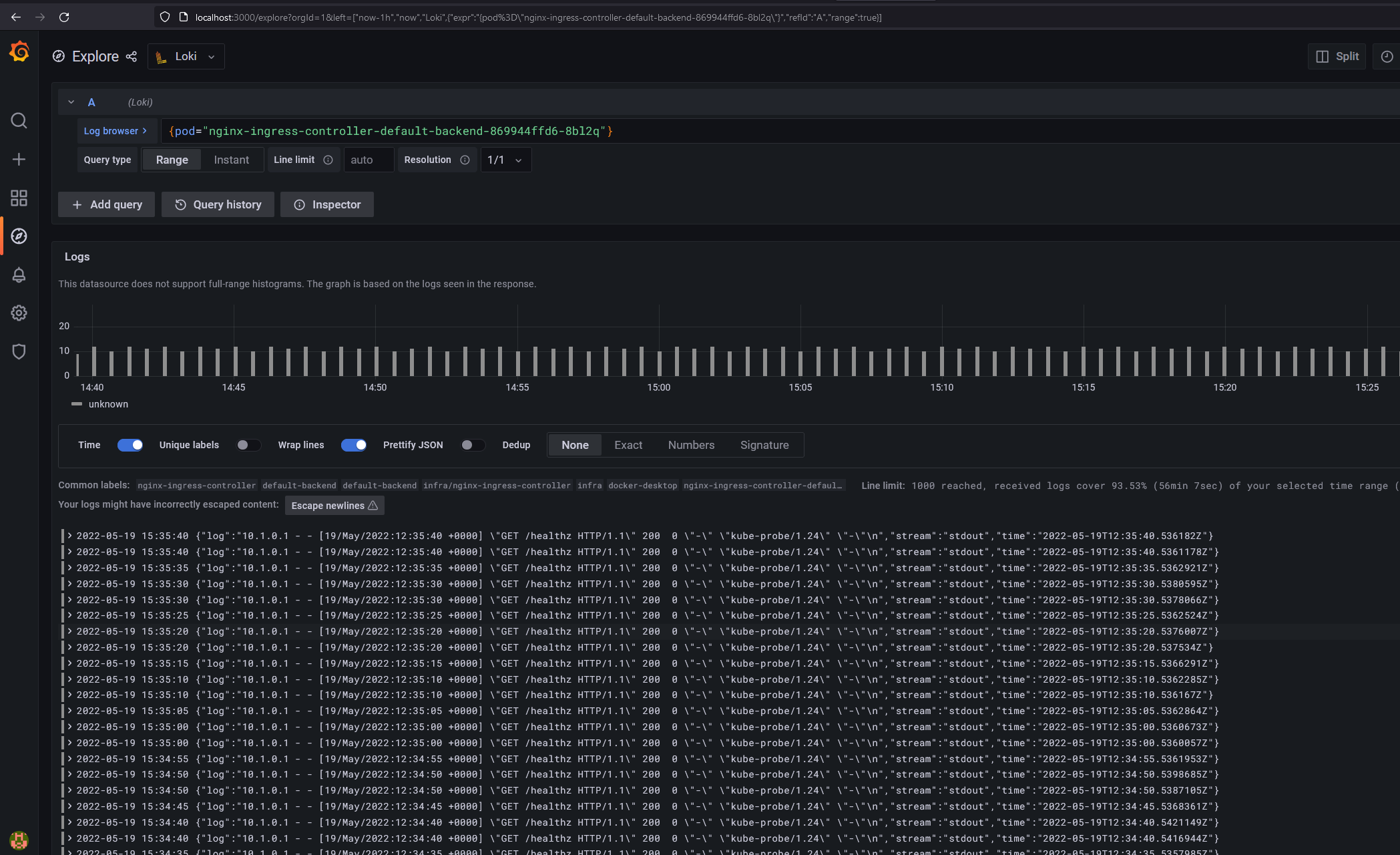
И нажав на Show Logs проверить, что логи пода доступны:
Заключение
В статье был рассмотрен один из возможных способов деплоя приложений в кластер кубера через flux на примере стека мониторинга: grafana, victoriametrics, loki. Вероятно, такой вариант деплоя может показаться сложным\сомнительным\непонятным и т.д. Возможно, так оно и есть.
Но есть и другая сторона медали, для чего всё это надо: с новыми подходами и терминами (что-угодно-code и что-угодно-ops) формируются различные понимания у разных групп людей. Кто-то вообще привык делать «по классике»: установка софта полностью вручную или же хранить все конфиги в гите, но деплой из гита осуществлять также вручную или через ansible и т.п.
И есть те, кто использует новые возможности и подходы, которые имеют цель унифицировать процессы в определенных направлениях. Так, сказав что «у меня деплой через Flux», любой знакомый с этим подходом сможет понять о чём речь, потому что там нет двойственного понимания — kustomization, helmrelease и т.д. — всё это всегда одинаково.
Тем не менее наличие множества вариантов решения проблем (вариантов деплоя в рамках статьи) — это тоже хорошо и даёт большой выбор. Но в то же время есть нюансы, когда невозможно изучить все инструменты и все подходы на экспертном уровне. Это вообще проблема всего IT — каждый раз выходит что-то новое, будь то фреймворк или язык программирования, и какие-то уже сформировавшиеся подходы устаревают, потому что «это было актуально вчера».
Именно поэтому и видится будущее за унифицированными и стандартизированными подходами, которые появлялись последние года: контейнеризация, оркестрация, CIOps, GitOps…даже в случае выхода чего-то нового, всё это можно будет вписать в уже существующее — новый фреймворк и приложение на нём будет работать условно на любом железе любой операционной системы в Kubernetes, а процесс деплоя и мониторинга этого приложения будет стандартизирован и описан в Git.
И хотя есть споры и критика концепции GitOps в сравнении с CIOps, в любом случае — это уже какие-то негласные стандарты, а также конкуренция (flux vs argocd и т.п.), что хорошо для развития продукта. Но это уже тема отдельной статьи, для которой нужно обладать должной экспертизой.