Введение
В данной статье будет рассказано о том, как настроить на базовом уровне отказоустойчивый кластер из двух серверов с Nginx на борту, используя Pacemaker и Corosync с применением Virtual IP.
Необходимость настройки кластера возникает тогда, когда появляется реальная потребность в обеспечении отказоустойчивости сервисов и приложений. Есть много различных вариантов по организации отказоустойчивости: начиная от планирования архитектуры в целом, железа, софта и заканчивая комплексным подходом с резервированием серверов, каналов связи, оборудования и даже дата-центров.
В данном же случае будет описан частный случай организации базовой отказоустойчивости посредством использования открытого программного обеспечения. Я не зря уточнил про реальную необходимость применения кластерного решения, т.к. кластер — это дополнительный уровень сложности, и при возникновении с ним проблем и не знании всех нюансов, время на траблшутинг может возрасти в несколько раз по сравнению с тем случаем, если бы кластер не применялся.
Это всё к тому, что решений по настройке кластера может быть много, но нужно с умом подходить к выбору стека и осознанно понимать, что, для чего и когда стоит настраивать, а когда — нет.
Принцип работы кластера
Часто Nginx используют в качестве обратного прокси: в таком случае Nginx обычно является первичной точкой входа для L7\L4 трафика, который уже распределяется до бэкендов. Соответственно, первым шагом обеспечения базовой и относительно простой отказоустойчивости будет резервирование Nginx, чтобы в случае возникновения проблем трафик мог дойти до конечного сервера с приложением.
Для примера я нарисовал простую архитектуру условного приложения, в которой отображен схематично принцип работы кластера:
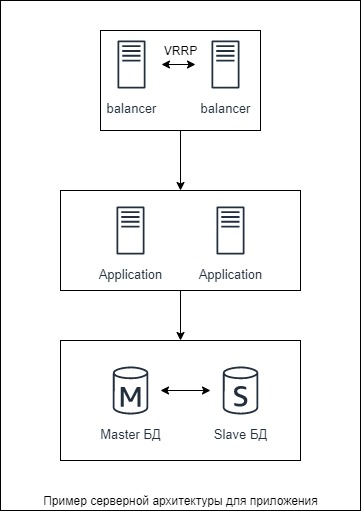
Пусть будет простое приложение: трафик приходит с сетевого оборудования (для нас это чёрный ящик и про это не думаем) на Nginx, с него попадает на backend и бэк обращается к СУБД в Master-Slave репликации. В данной схеме базово настроен горячий резерв: всегда есть запасной сервер приложений и slave-сервер БД. С этим понятно — просто два сервера приложений и обычная репликация для базы.
А вот суть резервирования точки входа трафика заключается в использовании протокола VRRP. VRRP может настраиваться как на сетевом оборудовании, которое располагается перед сервером с Nginx, так и непосредственно на Linux-сервере с использованием различных реализаций VRRP — про второй случай и будет описано далее. Отвечать за всю логику будет pacemaker и corosync в связке между собой на обоих серверах (т.е. организуется кластер). Соответственно, Nginx устанавливается на оба сервера, которые должны быть абсолютно идентичны: с одинаковыми настройками и конфигурационными файлами.
В кластере настраивается «общий» виртуальный IP-адрес (далее — Virtual IP, VIP), помимо уже существующих IP-адресов на серверах с Nginx. Этот VIP назначается одному из серверов кластера и в текущий момент времени будет работать только один сервер. Как только сервер с VIP выходит из строя, его адрес VIP сразу же забирает себе второй сервер кластера, т.к. в фоновом режиме, условно говоря, будет происходить постоянный healthcheck: каждый из серверов кластера будет проверять, жив ли его сосед.
Принцип работы достаточно прост: работает всегда один сервер, а второй на подхвате и моментально вступает в работу. Но есть всякого рода нюансы относительно кластерного решения в целом, о которых в рамках данной статьи я рассказывать не буду, но очень советую ознакомиться в документации pacemaker. В частности, с таким понятием, как fencig (STONITH).
Ресурсы Pacemaker
Сам Pacemaker, настройка которого будет описана далее, по сути оперирует ресурсами: например, файловая система — ресурс, виртуалка — ресурс, nginx — ресурс. И все эти ресурсы управляются с помощью скриптов, большая часть которых уже готова к использованию.
В терминологии Pacemaker есть простые ресурсы — это могут быть юниты systemd и т.п., т.е. на уровне системы инициализации. Тут всё просто: сервис может быть запущен, остановлен, перезагружен, в некоторых случаях поддерживается мягкая перезагрузка и вывод статуса. Но в случае с Nginx мало запустить ресурс в кластере. Как минимум нужно убедиться, что Nginx отдаёт 200 код ответа.
И тут в игру вступают OCF — некий формат скриптов для Pacemaker, с помощью которых можно более гибко получать данные мониторинга ресурса. А так как под капотом обычные скрипты (которые должны быть написаны с соблюдением стандарта OCF), то есть возможность реализовать очень много всего.
Для более подробного изучения работы Pacemaker лучше обратиться к оф. документации.
Архитектура Pacemaker
Весь конфиг кластера хранится в XML-формате в CIB (Cluster Information Base) и хранится на активной ноде, в терминологии pacemaker — это DC (Designated Controller). В случае аварии роль DC подхватывает моментально доступный сервер в кластере.
Сам Pacemaker состоит из множества компонентов (причем от версии 1 к версии 2 наименования компонентов изменялись). Опишу основные из них с актуальными наименованиями для второй версии Pacemaker:
- pacemaker-based (CIB) — как уже было сказано, хранилище конфигурации;
- pacemaker-attrd — хранит мета-атрибуты самого кластера, ресурсов, нод, агентов;
- pacemaker-controld — DC, главный сервер в кластере на текущий момент времени;
- pacemaker-execd (lrmd) — используется для локального ограждения (fencing);
- pacemaker-fenced — используется для локального и удаленного ограждения.
Corosync
Для синхронизации состояния кластера, получении информации о кворуме и сервисных сообщениях используется corosync. По сути он представляет из себя API для Pacemaker, и в большинстве случаев вручную настраивать его не приходится, т.к. всё делает сам Pacemaker при настройке кластера.
Настройка
Подготовительные работы
- На всех балансировщиках в /etc/hosts добавить записи:
10.10.4.10 srv-gate-1
10.10.4.20 srv-gate-2- Установить Pacemaker и Corosync со всеми зависимостями из дефолтных репозиториев centos:
yum install -y pcs pacemaker resource-agents- Установить Nginx из официальных репозиториев nginx.repo
cat > /etc/yum.repos.d/nginx.repo << EOF
[nginx]
name=nginx repo
baseurl=https://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=0
enabled=1
EOF- Выполнить установку и запуск:
yum -y install nginx && systemctl enable nginx --now- Определиться с Virtual IP. В данном случае будет 10.10.4.30.
Настройка HA
Выполнить на всех нодах:
- Задать пароль кластерного пользователя на всех нодах (желательно должен быть одинаковый):
passwd hacluster- Сделать enable для Pacemaker и Corosync (последний на данном этапе не запустится — это нормально):
systemctl enable pcsd corosync --now- Выполнить на любой одной ноде:
pcs cluster auth srv-gate-1 srv-gate-2- Создать логический кластер, указав DNS-имена из /etc/hosts:
pcs cluster setup --enable --start --name ha-gate srv-gate-1 srv-gate-2- Проверить, что кластер создан и corosync теперь запущен:
systemctl status -l corosync && pcs cluster status
PCSD Status:
srv-gate-1: Online
srv-gate-2: Online- Отключить Shoot-The-Other-Node-In-The-Head (обратить внимание, для продакшена желательно не отключать):
pcs property set stonith-enabled=false- Игнорировать кворум (обратить внимание, для продакшена желательно не игнорировать):
pcs property set no-quorum-policy=ignore- Создать ресурс с указанием VIP и 24 маски:
pcs resource create VIP ocf:heartbeat:IPaddr2 nic=ens192 ip=10.10.4.30 cidr_netmask=24 op monitor interval=5s --disabled --group ha-gate- Запустить VIP:
pcs resource enable VIP- Запустить
crm_mon -Afдля проверки, что VIP успешно запущен на одной из нод.
- Переместить явно VIP на другую ноду и проверить, что VIP пингуется:
pcs resource move VIP srv-gate-1- Создать ресурс для nginx с соответствующим именем (:
pcs resource create nginx ocf:heartbeat:nginx \
configfile=/etc/nginx/nginx.conf \
op monitor interval=5s- Клонировать на все ноды:
pcs resource clone
nginx- Сделать привязку агента, чтобы nginx запускался всегда на том же сервере, где и VIP:
pcs constraint colocation add VIP with nginx-clone- Добавить порядок запуска агента:
pcs constraint order start nginx-clone then start VIP- Очистить кластер от ошибок:
pcs resource cleanup- Для мониторинга состояния можно использовать команду:
crm_mon -Af- Для получения всех настроек ресурса в XML:
crm_resource --meta --resource nginx-clone --query-xmlОшибки при эксплуатации
В процессе работы кластера могут возникать различные ошибки. Здесь я опишу некоторые из них, с которыми приходилось сталкиваться.
- A processor failed, forming new configuration
Данная ошибка возникает, когда узлы теряют друг друга из поля зрения, т.е. не могут получить нужный токен. Это означает, что нужно применять политики ограждения, т.н. fencing, и «отстреливать» потерявшиеся узлы. Причиной возникновения таких ситуаций в моём случае являлось перемещение виртуальных машин с одного хоста гипервизора на другой при нехватке памяти на гипервизоре. Для меня, как для админа со стороны эксплуатации, это происходило совсем незаметно, т.к. ВМ и виртуализацией заведуют в ЦОД, где всё располагается, но при миграции это косвенно сказывается на работе кластера pacemaker&corosync.
Заключение
В рамках данной статьи был настроен простой кластер из Pacemaker+Corosync и Nginx, который после понимания теории просто настраивается и сразу же готов к работе. Для production стоит настроить fencig, т.е. ресурсы ограждения, а также использовать три сервера в кластере как минимум, чтобы был кворум, т.е. согласованность. Кворум определяет минимальное число активных нод в кластере, при котором кластер считается работоспособным. Обычно кластер считается неработоспособным, если количество активных нод меньше половины от общего числа узлов.
Также для кворума не обязательно использовать нечетное количество серверов с аналогичными характеристиками. Так, например, при наличии двух серверов в кластере, на которых запущены ресурсы, можно создать третий сервер в качестве арбитра с минимальными ресурсами, т.е. сервер будет исполнять только роль наблюдателя для кворума.
Помимо Nginx в Pacemaker может быть любое другое ПО в качестве ресурса, которое можно «обвесить» скриптами и использовать для failover или чего-либо ещё. Например, по этой же статье можно настроить такой же кластер из Nginx, но уже в docker:
pcs resource create nginx-docker ocf:heartbeat:docker image=nginx:1.19.3 reuse=true allow_pull=true run_opts="-d -v /mnt/u01/nginx/etc/nginx/conf.d:/etc/nginx/conf.d -v /etc/nginx/ssl:/etc/nginx/ssl -p 80:80 -p 443:443" op monitor interval=30sВозможности тут не сильно ограничены и можно этот кейс использовать там, где нет нативного failover.
В документации компании ClusterLabs есть примеры с настройками различных сервисов в кластере, а также ресурсы, которые можно добавить к себе на сервер.